正则表达式
正则表达式的引出
如何从文本中提取自己想要的内容呢?
可以通过 正则表达式 实现这一目的。简单的说,正则表达式就是从文本中,按照一定规律,寻找子文本。例如从“订单号:123456789”中获取订单号的数字。在影刀中,可以用【从文本中提取内容】这个指令,使用正则表达式。
正则表达式的常用操作符
| 操作符 | 含义 | 示例 |
|---|---|---|
. |
表示任何单个字符 | |
[] |
字符集,对单个字符给出取值范围 | [abc]表示a或b或c,[a-z]表示a-z单个字符(任意一位小写字母) |
[^] |
非字符集。对单个字符给出排除范围 | [^abc]表示非a或b或c的单个字符 |
* |
前一个字符的0次或者无限次的扩展 | abc*表示ab、abc、abcc、abcccc等等(匹配 ab) |
+ |
前一个字符的1次或者无限次的扩展 | abc+表示 abc、abccc、abcc、abccccc等(不匹配 ab) |
? |
前一个字符的0次或者1次扩展 | abc?仅表示 ab、abc |
| |
左右表达式中的任意一个 | abc|def表示abc、def |
{m} |
扩展前一个字符m次 | ab{2}c表示abbc |
{m,n} |
扩展前一个字符m至n次(含m和n次) | ab{1,2}c匹配abc、abbc |
^ |
匹配字符串开头 | ^abc表示abc在一个字符串的开头,即不匹配 aabc |
$ |
匹配字符串结尾 | abc$表示abc在一个字符串的结尾,即不匹配abcd |
() |
分组标记内部只能使用|操作符 |
(abc)表示abc ,(abc|def)表示abc、def |
\d |
一位数字,等价于[0-9] |
|
\w |
组成单词的字符,等价于[A-Za-z0-9_] |
表示字符小写大写的a-z和数字0-9以及下划线_ |
经典的正则表达式
| 表达式 | 含义 |
|---|---|
^[A-Za-z]+$ |
由26个字母组成的字符串 |
^[A-Za-z0-9]+$ |
由26个字母和数字组成的字符串 |
^-?\d+$ |
整数形式的字符串 |
^[0-9]*[1-9][0-9]*$ |
正整数形式的字符串 |
[1-9]\d{5} |
中国境内邮政编码 |
[\u4e00-\u9fa5] |
匹配中文字符 |
\d{3}-\d{8}\|d{4}-\d{7} |
国内固定电话号码 |
案例
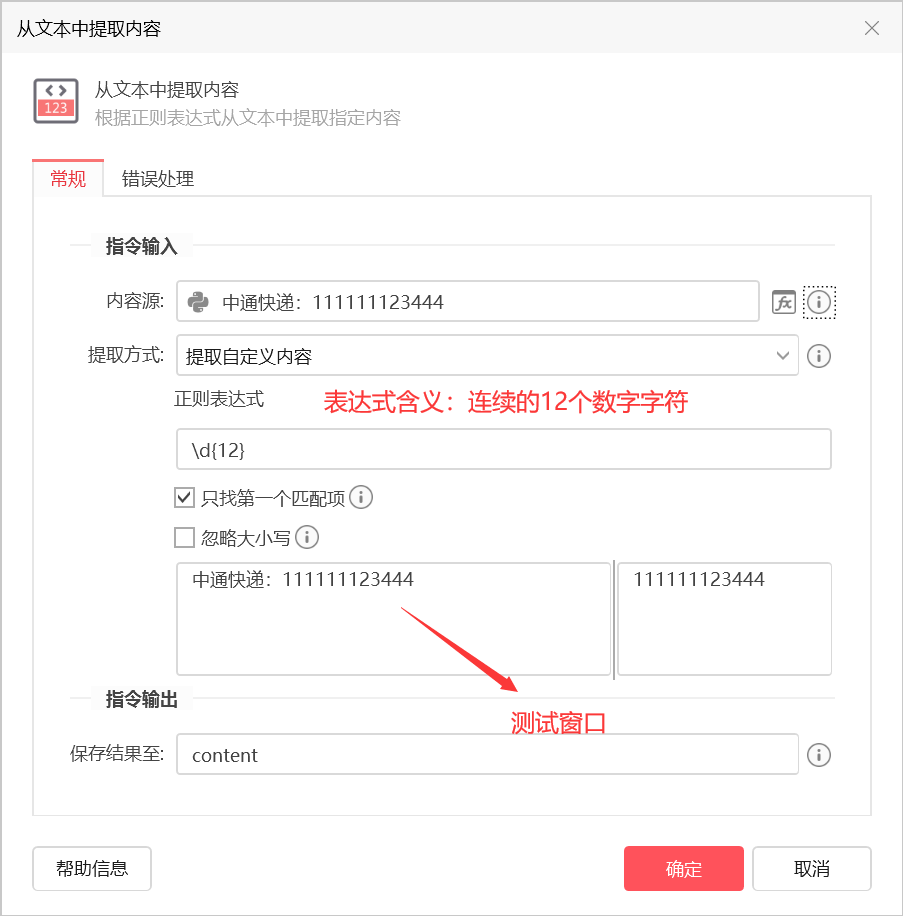
通过连续数字的长度,匹配物流编号
- 明确物流单号位数,如中通快递:111111123444,有12位
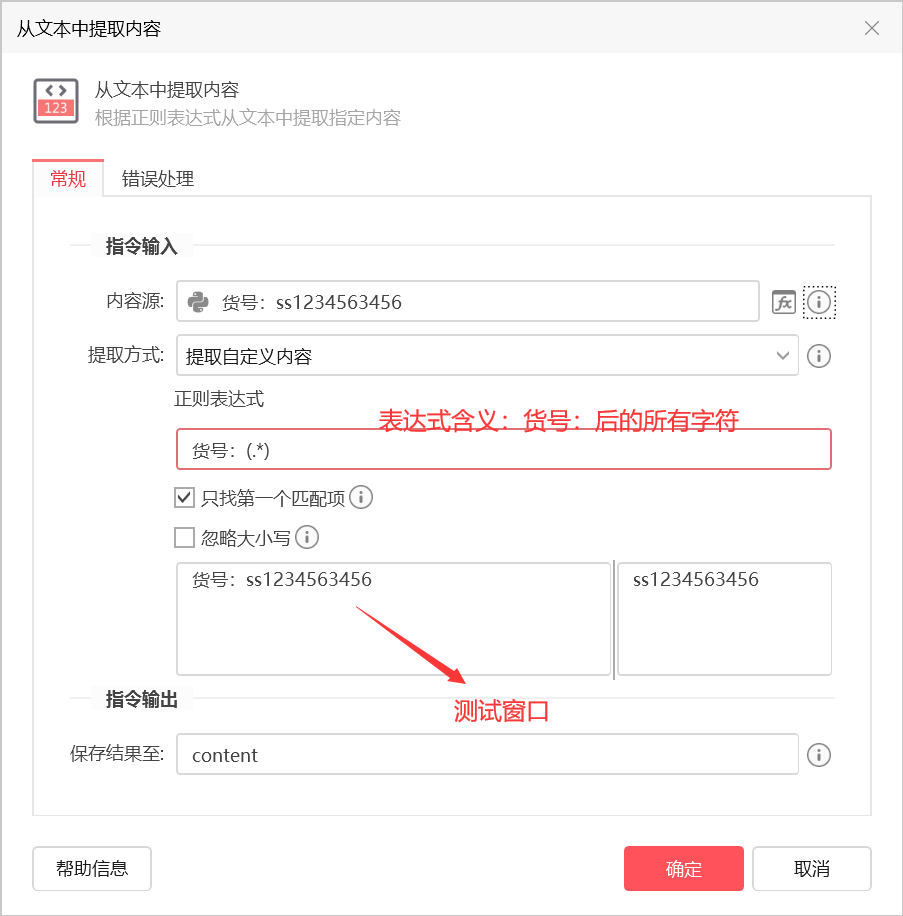
通过前缀文字,匹配货号
- 从文本中截取自己想要的东西,如:货号:ss1234563456